Mesurer ce qui compte : un cadre d'évaluation pour la segmentation d'instance en conditions réelles
Par Jacob Cossette
Un projet en vision par ordinateur comparant SOLOv2, Mask R-CNN et U-Net pour la segmentation de déchets, et la méthodologie d'évaluation conçue pour les comparer équitablement.
Le problème
La détection automatique de déchets paraît simple jusqu'à ce qu'on tente de la déployer. Un centre de tri ou un dispositif mobile d'inspection doit segmenter, pas seulement classifier, plusieurs déchets souvent superposés dans des scènes encombrées et mal éclairées, généralement sur du matériel avec peu de puissance de calcul. C'est cette dernière contrainte que la plupart des comparaisons ignorent : les publications rapportent la précision et rarement le budget de calcul nécessaire pour l'atteindre.
Ce projet visait à comparer trois architectures de segmentation d'instance, SOLOv2, Mask R-CNN et U-Net, pour la segmentation de déchets sur le jeu de données TACO (Trash Annotations in Context), avec une contrainte explicite : toute recommandation devait tenir compte des environnements à ressources limitées, pas seulement de la précision brute.
Trois architectures, trois philosophies de conception
SOLOv2 élimine complètement le pipeline « proposer des boîtes, puis segmenter ». Il prédit directement les masques à partir de la carte de caractéristiques via une branche kernel (génération dynamique de masques par cellule) et une branche feature, fusionnées par fusion pyramidale et nettoyées par suppression des maxima non pertinents (NMS). Sa fonction de perte combine la Focal Loss (pour gérer le déséquilibre des classes, car la plupart des cellules de la grille ne contiennent aucun objet) et la Dice Loss (pour affiner les contours des masques, utile pour de petits déchets aux formes irrégulières).
Mask R-CNN s'appuie sur Faster R-CNN, en ajoutant une branche de segmentation à la classification et à la régression des boîtes englobantes. RoIAlign corrige le désalignement au niveau du pixel entre les propositions de région et la carte de caractéristiques, un détail qui compte pour des contours de déchets précis. Sa perte est une somme pondérée de trois termes indépendants : classification (entropie croisée), régression de boîte (Smooth L1) et prédiction de masque (entropie croisée binaire par pixel).
U-Net a servi de modèle de référence pour le projet. Sa structure encodeur-décodeur avec sauts de connexion réinjecte directement dans le décodeur les détails fins de bas niveau (contours, textures) captés par l'encodeur, un point important lorsque les objets sont petits ou partiellement masqués, ce qui est fréquent pour des débris dispersés.
Concevoir une comparaison équitable
Le détail technique le plus important ici n'est pas une architecture en particulier. C'est la discipline de garder les variables constantes pour que la comparaison ait réellement un sens :
Mêmes backbones pour tous les modèles. ResNet-50 et ResNet-18, tous deux préentraînés sur COCO, testés indépendamment afin d'isoler l'empreinte en ressources du backbone de celle de la tête du modèle.
Même jeu de données. TACO : 1 500 images officiellement annotées, 28 super-catégories, 60 sous-catégories, masques annotés manuellement au format COCO, avec des arrière-plans réalistes et variés (un choix délibéré par rapport à des jeux de données plus propres mais moins représentatifs).
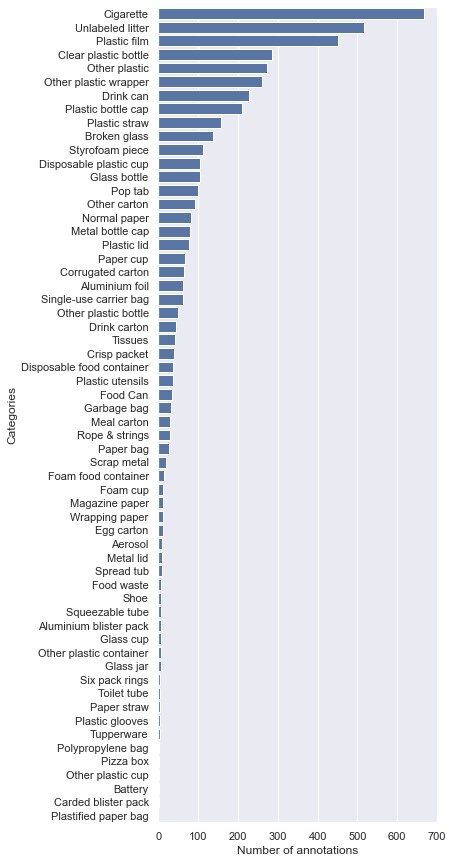
La distribution à traîne longue des catégories de TACO — une poignée d'objets courants (mégots, film plastique, bouteilles) domine, avec des dizaines de sous-catégories plus rares dans la traîne. C'est exactement ce déséquilibre que la Focal Loss de SOLOv2 est conçue pour compenser.
Même régime d'entraînement. Taux d'apprentissage de 0,0001, taille de lot de 10, 30 époques, un seul worker, exécuté dans un environnement Conda figé (CUDA 11.7, PyTorch 2.0.0, MMCV 2.0.4, MMDetection), pour que les résultats soient reproductibles et attribuables à l'architecture plutôt qu'à un hyperparamètre ou une version de bibliothèque non contrôlée.
Sans cela, un titre du genre « SOLOv2 bat Mask R-CNN » ne veut rien dire. Cela pourrait simplement signifier qu'un modèle a eu un meilleur backbone ou un entraînement plus long.
Le cadre de mesure : trois axes, pas un seul
C'est la contribution centrale du projet : la précision seule ne répond pas à la question du déploiement, donc l'évaluation a été conçue autour de trois axes indépendants.
1. Précision : mAP. La moyenne des précisions (mAP) à des seuils d'IoU de 0,5 et de 0,5:0,95, calculée en mesurant le recouvrement entre les masques prédits et la vérité terrain. Standard en vision par ordinateur, et nécessaire, mais insuffisante à elle seule. Suivie via les journaux TensorBoard générés lors des inférences afin que les résultats soient comparables d'un essai à l'autre.
2. Efficience : seuil de recouvrement. Un critère de réussite ou d'échec plus strict et orienté déploiement, en complément du mAP : un masque prédit n'est compté comme une détection correcte que si au moins 50 % de sa surface recouvre la vérité terrain. Cela répond à une question plus opérationnelle que le mAP seul, à savoir si le modèle produit des détections utilisables assez souvent, plutôt qu'un score de précision moyenné qui peut masquer un comportement incohérent.
3. Utilisation des ressources : FLOPs et nombre de paramètres. Mesurés avec l'outil get_flops.py de MMDetection pour chaque combinaison modèle, backbone et taille d'image. Puisqu'une des questions sous-jacentes du projet était de savoir si l'un de ces modèles est viable dans un agent à ressources limitées (matériel de tri embarqué, appareil mobile), le coût de calcul devait être une métrique de premier plan, pas une réflexion secondaire abordée seulement si la précision le permettait.
L'objectif de structurer l'évaluation ainsi : un modèle qui gagne sur le mAP mais nécessite 4 fois plus de calcul n'est pas automatiquement la bonne réponse pour toutes les cibles de déploiement. Rendre ce compromis visible était le véritable objectif. Les chiffres précis étaient secondaires par rapport au fait d'avoir une méthodologie qui fait ressortir ce compromis.


Une photo brute de TACO (en haut) et la sortie de segmentation d'instance correspondante (en bas) — six déchets distincts isolés dans une scène de rue encombrée et inégalement éclairée. C'est la difficulté du quotidien que le cadre d'évaluation devait prendre en compte : objets superposés, ombres marquées, aucun arrière-plan propre sur lequel se replier.
Quand le pipeline flanche : la partie que l'évaluation est vraiment
La partie honnête de ce projet est que les résultats finaux tête-à-tête n'ont jamais été pleinement produits, et il vaut la peine d'expliquer pourquoi, car les diagnostiquer a représenté autant de travail que la comparaison des architectures elle-même.
MMDetection et TACO sont tous deux essentiellement non maintenus; TACO n'a pas fait l'objet de maintenance active depuis environ quatre ans. Cela s'est traduit par des problèmes concrets et bloquants : identifiants d'annotation dupliqués, images manquantes et annotations incohérentes dans le jeu de données, en plus d'exigences de versions de bibliothèques non documentées et incompatibles entre PyTorch, CUDA et MMDetection dans l'outillage. Chacun de ces problèmes a dû être diagnostiqué et corrigé manuellement : dédoublonnage des entrées, complétion des fichiers manquants et rétrogradation de versions précises de bibliothèques jusqu'à ce que le pipeline fonctionne de bout en bout.
Un cadre d'évaluation n'est fiable que si le pipeline qui l'alimente l'est aussi. Un ensemble de métriques parfaitement conçu ne vaut rien si les données en dessous sont silencieusement corrompues, ce qui explique pourquoi ce travail de débogage fait partie de l'histoire de l'évaluation plutôt qu'une note de bas de page.
Tirer des conclusions de façon responsable
Avec un pipeline d'entraînement maison encore instable à l'échéance du projet, le choix était entre forcer un chiffre partiel ou trompeur et être explicite sur ce qui pouvait être affirmé ou non. J'ai choisi la deuxième option. Plutôt que de présenter des résultats internes incomplets comme définitifs, le rapport s'appuie sur une expérience comparable et révisée par les pairs (Xu et al., 2024, sur la segmentation de déchets avec TACO), qui a montré Mask R-CNN en tête sur le mAP et le mAP50, tandis que SOLOv2 était plus rapide et plus léger en ressources. C'est cohérent avec ce que la comparaison d'architectures ci-dessus laisserait prévoir, mais c'est explicitement cité, et non présenté comme un résultat propre à ce projet.
Cette distinction, entre ce qui a été mesuré ici et ce qui est cité d'ailleurs, fait elle-même partie de la discipline d'évaluation. Une recommandation n'est crédible que si l'évaluateur est clair sur la nature de ses propres preuves.

Filtrage par classe sur le même pipeline d'évaluation : seule la classe « plastique » est affichée ici, isolant une bouteille coincée contre une bordure. Les questions orientées déploiement, comme « a-t-on bien détecté le plastique », exigent souvent ce niveau de détail par classe, pas seulement un mAP agrégé.
Ce qu'il faut en retenir
Concevoir la comparaison comme une expérience contrôlée : fixer les backbones, le jeu de données et les hyperparamètres d'entraînement avant de comparer quoi que ce soit d'autre. Évaluer selon des axes indépendants, puisque la précision, l'efficience et l'utilisation des ressources répondent chacune à une question de déploiement différente, et les réduire à un seul score masque le compromis qui compte réellement. Traiter le pipeline de données et d'outillage comme quelque chose qui doit lui-même être validé; des frameworks non maintenus et des jeux de données dégradés sont la norme, pas l'exception, en apprentissage machine appliqué. Et être précis sur la frontière entre résultats mesurés et résultats cités, surtout quand la réponse honnête est que le pipeline n'a pas abouti à temps.
Cette même discipline, faite de métriques multi-axes, de comparaisons contrôlées et d'une gestion rigoureuse de données et d'outillage imparfaits, est celle que j'applique aujourd'hui à l'évaluation de systèmes d'IA en production, y compris des flux de travail agentiques basés sur des LLM, où « est-ce que ça fonctionne » n'est pas non plus une question qui se résume à un seul chiffre.
Télécharger le rapport complet (PDF) : revue de littérature complète, dérivation des fonctions de perte, analyse du jeu de données, annexe de code et spécification de l'environnement.